In which we discuss how the new features added into Dell EMC PowerFlex 3.6 give customers better outcomes, including more control of their Replication Consistency Groups.
A lot can happen in a year, and the past year has certainly been unlike any other, for reasons that really do not need to be repeated here. However, it is amazing to think that it was only one year ago that Dell EMC released PowerFlex 3.5, which added native asynchronous replication to the growing list of data services provided by PowerFlex to its customer base, many of who were itching to test drive replication for themselves. Now, just a little over one year later, version 3.6 has seen its GA release, and with it, key improvements have been made to the replication capabilities on offer that will give customers better flexibility in architecting storage-level DR solutions running on top of PowerFlex.
Removing the Replication “Training Wheels”….
Customers use PowerFlex for a number of reasons, but the keys ones tend to be its ability to provide a highly performant, self-healing, highly available, software-defined block storage platform that scales like nothing else in the market! So when PowerFlex 3.5 was released last year, our Engineering Team adopted a “crawl… walk.. run” posture with regards to adding replication into the product. The aim was to ensure that we added the async replication capability without compromising the core strengths of the product. To do this, a few choices were made to ensure that we were successful with the release of 3.5. We took the decision to only support replication on Storage-Only nodes with this release, plus we also decided that, out of the gate, 30 seconds would be the minimum supported RPO time. We had extensively tested the replication capability with a number of customers prior to the release of 3.5, but it is only after extensive field testing that you really get to understand how good something is!
Well, a year later and the results are in – the feedback has been very positive, with many customers now having replication enabled between PowerFlex clusters. More importantly, my colleagues in support have not been unduly troubled by calls from irate customers, which is always satisfying to hear – kudos to the PowerFlex Engineering Team for doing such a great job in the first place!
More importantly, the success of the native replication capability has allowed us to expand the replication use cases – starting with PowerFlex 3.6, replication is now also supported when running on HCI nodes running VMware ESXi 7.0u2. With this release and the latest version of PowerFlex Manager, customers can now deploy a replication service on HCI PowerFlex nodes. For those PowerFlex customers currently running earlier versions of VMware and who wish to upgrade to PowerFlex 3.6 as well as upgrade to ESXi 7.0u2, PowerFlex Manager will automate the upgrade process for both Hyperconverged (HCI) or Two-Layer (Compute-Only) VMware deployments. Meaning that PowerFlex Manager will handle the resizing of the PowerFlex SVMs on HCI nodes, as well as coordinate the creation of three vCLS VMs that are now needed thanks to the recent introduction of vSphere Cluster Services.
Plus, by releasing a PowerFlex SRA for VMware Site Recover Manager, our customers can also fully manage their replication & DR scenarios by using either SRM 8.2 or 8.3. The PowerFlex SRA architecture is shown in the figure below:
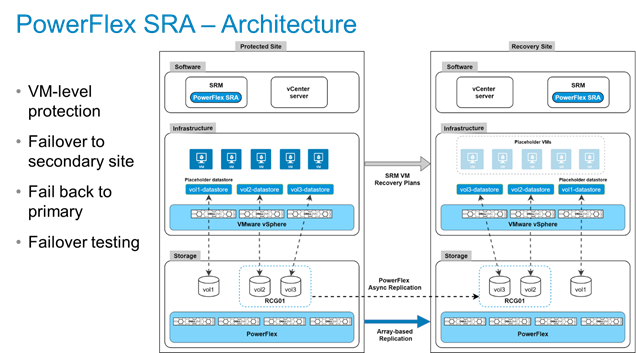
Figure 1 – PowerFlex SRA Architecture
It should go without saying that you need two PowerFlex 3.6+ clusters, peered and already configured for replication before trying to install the PowerFlex SRA into SRM. There must also be at least one active Replication Consistency Group already running. The VMs to be protected reside in datastores created from PowerFlex volumes. Note that SRM requires a small, non-replicated placeholder datastore at each site, where the placeholder VM information is saved. The flow of steps needed are quite trivial:
- Map the RCG volume(s) to the vSphere cluster datacenter nodes, these should be set Read/Write on the primary site ESXi hosts
- Create VMFS datastore(s) on the primary site
- Mount the datastore(s) to all nodes on the primary site
- Then map replicated volumes as Read-only on Secondary site ESXi hosts
- Create or migrate VMs on to the replicated PowerFlex-based datastore.
Obviously, SRM requires that the administrator configures “Protection Groups” and “Recovery Plans” for the VMs residing on the PowerFlex volumes that are part of the active RCGs. Once these have been created, then the vSphere administrator can easily administer failover, failback & DR test activities from within SRM.
As well as supporting more use cases, the RPO time supported by PowerFlex 3.6 has been cut in half, so 15 seconds is now supported. As you can see, by supporting more use cases and giving lower RPOs, the ‘training wheels’ have been removed and we are building up momentum… But there is more replication goodness in PowerFlex 3.6!
Introducing the “Inactive State” for Replication Consistency Groups
In PowerFlex 3.5.x, a user had no way of maintaining a Replication Consistency Groups’ (or RCGs for short) configuration of replication Pairs without the actual replication happening and journal and network resources being consumed. Also, in the rare case where the system became incapable of continuing the replication of an RCG – say for example, because there was no free journal space, or the network link had dropped between sites – then eventually, the replication metadata could be deleted. The downside of this being that if the replication metadata was discarded for any reason, then the system could only delete the RCG completely from the system. Recovery from this would need an admin user to intervene and re-create the RCG, which would automatically trigger an initial copy – and remember that an initial copy is a full copy.
Understandably, having to re-create and then fully resynchronise RCGs because of a full journal or slow/dropped network link is something that storage administrators want to avoid at all costs. Thankfully, in PowerFlex 3.6, we have added a new ‘Activate-Deactivate RCG’ feature, which introduces a new INACTIVE state for RCGs. This is very useful for those times when users do not want or need replication to occur. When an RCG is in the INACTIVE state, no replication activities occur, meaning that no journal or network resources are consumed – handy if you want to drop a “lower priority” RCG in order to free up precious replication resources for other RCGs that are deemed more business critical. Also, in the cases where the system is unable to continue replication due to lack of resources, it will automatically move the RCG to the INACTIVE state. Obviously, this gives much better outcomes for PowerFlex users and administrators.
This also means that if users can now create an RCG in the INACTIVE state to begin with, it also allows them to move the RCG into the normal, ACTIVE, state, and back again at will, giving much better replication control.
Introducing “Partial Consistency” to PowerFlex Replication
When an RCG is in an INACTIVE state, it also allows the RCG configuration to be modified. Replication volume pairings can be created, deleted, modified, all before starting actual replication. Adding this flexibility into RCG management leads us nicely onto the new term added in this release, namely “Partial Consistency”. In PowerFlex 3.5, an RCG would be “Consistent” if all the volume pairs which completed the Initial Copy were consistent. However, in the case where some of the volume pairs completed the Initial Copy (and were therefore consistent from a replication point of view), and other volume pairs did not complete the Initial Copy, PowerFlex 3.5 would still consider that the RCG was “Consistent”. Which clearly was not the case and so made it easy for administrators to get confused.
Whereas with the improvements made to PowerFlex 3.6 replication, we have now added the concept of “Partial Consistency”. This covers the scenario for any RCG where some of the volume pairs completed the Initial Copy and are truly Consistent, while other volume pairs may not have completed the Initial Copy – for example, when the user wants to add new volume pairings into the RCG. Hence, marking an RCG as having “Partial Consistency” makes much more sense and allows administrators to get a more accurate view of the overall state of their replication groups.
To Summarise…
Dell EMC PowerFlex customers using the native asynchronous replication capabilities introduced with PowerFlex 3.5 has been growing rapidly over the past year. Customers who wanted to take advantage of the PowerFlex “super powers” are impressed. They usually chose PowerFlex because they needed to implement a highly scalable, software-defined storage platform that delivers blindingly fast performance with amazing reliability and availability. The fact that we added native replication into our architecture over a year ago without compromising any of these foundational strengths was impressive enough – as we keep adding improvements into PowerFlex, it shows our customers that we are not content with to just sit back and consider this as “job done”. Watch out for even better capabilities being added into Dell EMC PowerFlex with future releases!

