Before jumping into the details of Fault Sets, a quick recap on how PowerFlex works (in VERY simple terms).
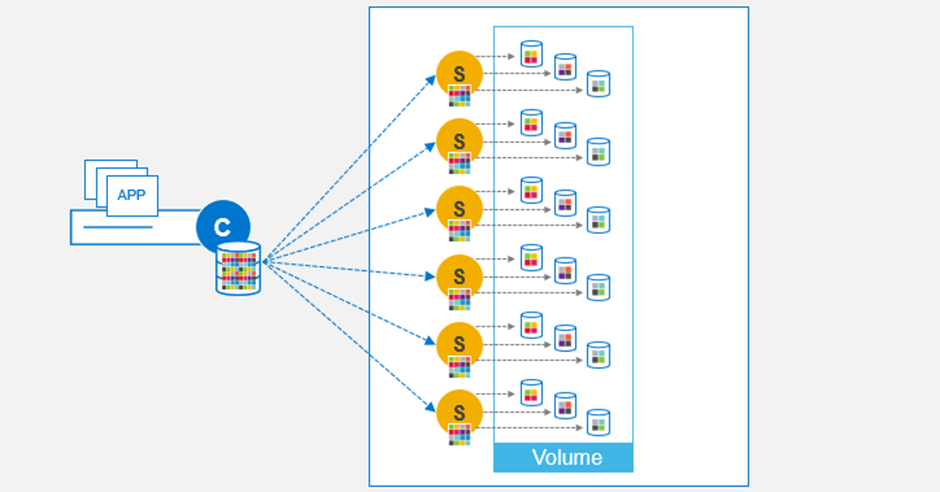
We take servers with locally attached disks, install the SDS (orange circle with an S in the diagram below), apply some magic and produce a software defined storage array. On the client systems that we want to access the storage, we install the SDC (blue circle with a C in the diagram) and this communicates with every SDS.
On this software defined storage array, we create a volume using a graphical interface, a command line or a REST API call and this is mapped to the client via TCP/IP over Ethernet. Now as the diagram below shows, every volume is broken into chunks and distributed across every disk on every node. Each chunk has a primary copy, written to one disk on one node and a secondary copy, written to another disk on a different node, we call this mesh-mirror.
The question we have, what happens in the event of a failure. The three main failure scenarios are the following:
- A network path failure
- A disk failure
- A complete node failure
The first one is easy. Network path failures are dealt with natively and completely seamlessly by PowerFlex. The SDC and SDS are aware of what network paths exist between them, they use them to provide resilience and load balancing, there is no requirement to add any form of complex network bonding or teaming into the environment. If a path goes down, PowerFlex will tell you, if the network is providing the resilience, then the network needs to be monitored for missing or failed links.
In the event of a disk failure, PowerFlex quickly detects this, it knows which chunks are on the failed disk and therefore which chunks on the remaining disks do not have a second copy. It immediately starts to create those second copies on the remaining disks across the nodes. Because every SDS on every node contributes to this rebuild process, it happens incredibly quickly.
Should an entire node fail, the system reacts in a very similar way to if a single disk fails, it rebuilds the mirrors as quickly as possible across the remaining nodes and disks. In this situation, the number of chunks is much larger because more disks are impacted, hence the time to rebuild is longer, it is still remarkably quick.
You may be asking yourself, how can these rebuilds happen if my disks are already full? This is a very valid question and why spare capacity must be reserved on the system at installation time. The spare capacity must be sufficient to protect against the failure of one entire node. It defaults to 10% of overall capacity, which is fine if there are 10 or more storage nodes, if there are fewer than 10 nodes, the system will warn you that spare capacity should be increased.
That covers the basic failure scenarios but what if I have a situation where my needs are slightly more complex. Let’s say I have my PowerFlex storage nodes installed across multiple racks and would like to be able to protect against an individual rack failure or be able to carry out maintenance on a rack – this is precisely where Fault Sets enter the game.
Consider the six storage nodes in our original diagrams above, installed across three separate data centre racks. By configuring each rack as a Fault Set, we can protect against its failure or for performing maintenance tasks. PowerFlex does this by not just ensuring the copy of a data chunk is on a separate node and disk, but that it is in a separate node and disk, in a different Fault Set.
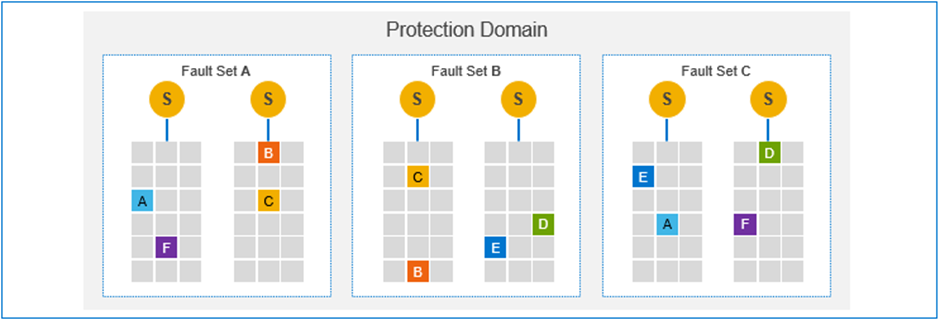
If a Fault Set fails, at least one copy of each chunk of data is still available on one of the other Fault Sets.
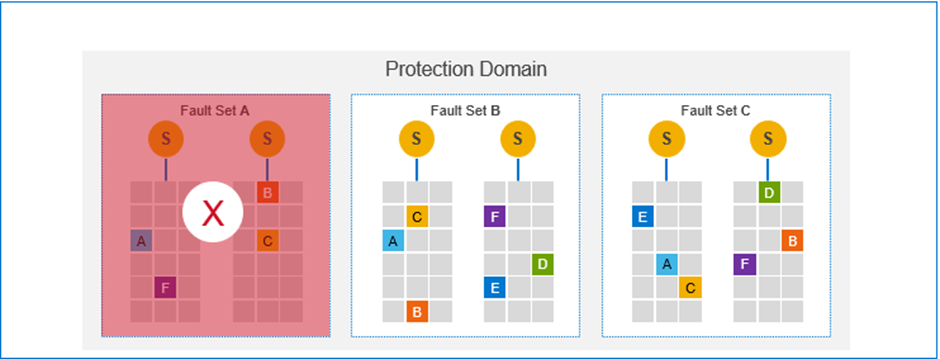
Of course, should this happen, PowerFlex will do exactly what it always does. It will immediately start rebuilding so that every chunk of data has two copies, its main focus is always to maintain high availability and performance.
The minimum number of Fault Sets is 3 and the maximum is 64.
What Fault Sets offer is really very simple, however it is very important to understand their impact on overall design of a PowerFlex environment.
For example, how do they affect the spare capacity required for rebuilds?
There must be sufficient spare reserved to cover the failure of an entire Fault Set, in the example above, a minimum one third of the capacity must be reserved as spare, if there were 8 Fault Sets, then an eighth, etc.
As has already been stated, PowerFlex will always look to rebuild as quickly as possible, this will mean a lot of network traffic between Fault Sets. If they are in separate data centre racks, each with their own top of rack network switches, this is going to generate significant network traffic up to the aggregation/spine and down again.
What if I want my Fault Sets is different data centres or buildings? This is, of course possible but the correct network design is vital.
Anyone that has seen the recent announcements about the capability of running PowerFlex in the public cloud, will have noticed the multi Availability Zone offering.
This uses Fault Sets exactly as describe above.
The multi Availability Zone option did cause some confusion amongst some people. I was approached by an individual who suggested that if they put their compute clients in one of the zones and it would only need to communicate with the storage nodes in that zone. This is of course not true the clients must still communicate with every storage node. It is just the internal placement of the data chunks that is changed.
That covers what Fault Sets are but now let’s see what we can do with them.
In a lab, I configured 24 storage/SDS nodes, arranged into 6 Fault Sets. Before my colleagues start accusing me of stealing servers, these are virtual machines, running on 6 physical R740xd VxFlex Ready Nodes. Using KVM, SR-IOV and disk pass-through, generated some very impressive performance numbers, even in this virtual environment.
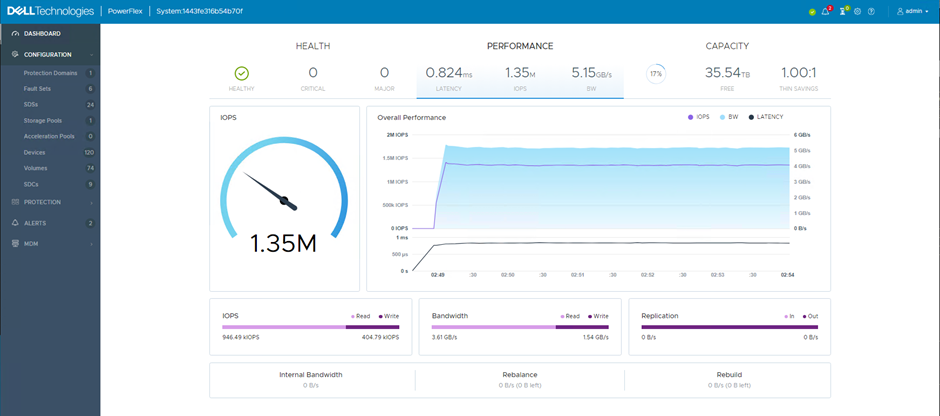
In the screenshots below, the first shows the storage/SDS nodes and the second shows the Fault Sets.
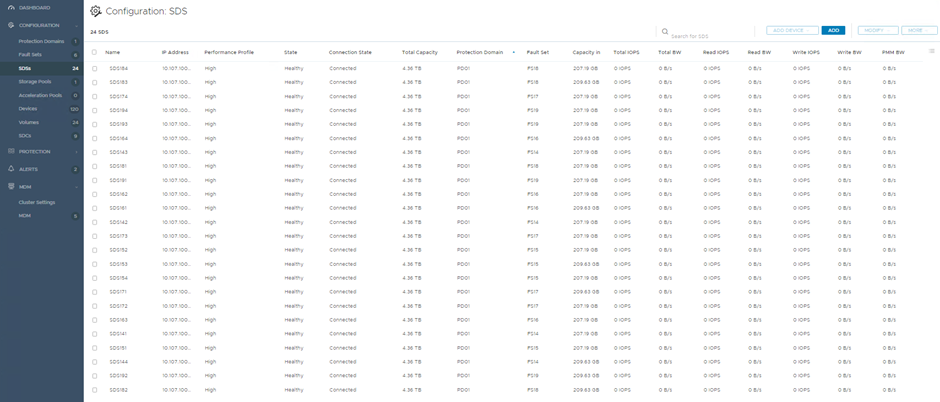
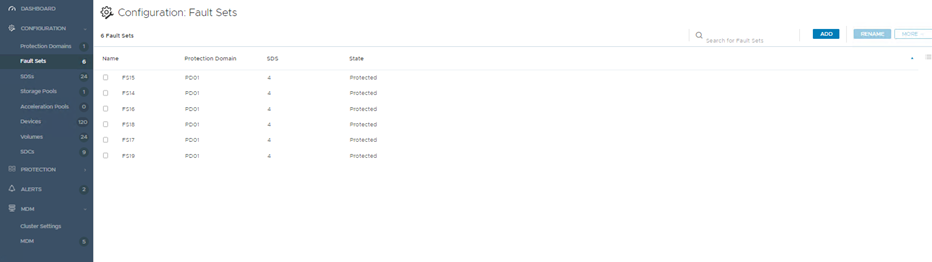
PowerFlex also provides a CLI option to view this information
# scli --query_all_sds Query-all-SDS returned 24 SDS nodes. Protection Domain 22faf2a000000000 Name: PD01 SDS ID: 055ae72000000017 Name: SDS194 State: Connected, Joined IP: 10.107.100.94,10.107.100.194,10.107.101.94,10.107.101.194 Port: 7072 Version: 3.6.300 SDS ID: 055ae71f00000016 Name: SDS193 State: Connected, Joined IP: 10.107.100.93,10.107.100.193,10.107.101.93,10.107.101.193 Port: 7072 Version: 3.6.300 SDS ID: 055ae71e00000015 Name: SDS192 State: Connected, Joined IP: 10.107.100.92,10.107.100.192,10.107.101.92,10.107.101.192 Port: 7072 Version: 3.6.300 SDS ID: 055ae71d00000014 Name: SDS191 State: Connected, Joined IP: 10.107.100.91,10.107.100.191,10.107.101.91,10.107.101.191 Port: 7072 Version: 3.6.300 SDS ID: 055ae71c00000013 Name: SDS184 State: Connected, Joined IP: 10.107.100.84,10.107.100.184,10.107.101.84,10.107.101.184 Port: 7072 Version: 3.6.300 SDS ID: 055ae71b00000012 Name: SDS183 State: Connected, Joined IP: 10.107.100.83,10.107.100.183,10.107.101.83,10.107.101.183 Port: 7072 Version: 3.6.300 SDS ID: 055ae71a00000011 Name: SDS182 State: Connected, Joined IP: 10.107.100.82,10.107.100.182,10.107.101.82,10.107.101.182 Port: 7072 Version: 3.6.300 SDS ID: 055ae71900000010 Name: SDS181 State: Connected, Joined IP: 10.107.100.81,10.107.100.181,10.107.101.81,10.107.101.181 Port: 7072 Version: 3.6.300 SDS ID: 055ae7180000000f Name: SDS174 State: Connected, Joined IP: 10.107.100.74,10.107.100.174,10.107.101.74,10.107.101.174 Port: 7072 Version: 3.6.300 SDS ID: 055ae7170000000e Name: SDS173 State: Connected, Joined IP: 10.107.100.73,10.107.100.173,10.107.101.73,10.107.101.173 Port: 7072 Version: 3.6.300 SDS ID: 055ae7160000000d Name: SDS172 State: Connected, Joined IP: 10.107.100.72,10.107.100.172,10.107.101.72,10.107.101.172 Port: 7072 Version: 3.6.300 SDS ID: 055ae7150000000c Name: SDS171 State: Connected, Joined IP: 10.107.100.71,10.107.100.171,10.107.101.71,10.107.101.171 Port: 7072 Version: 3.6.300 SDS ID: 055ae7100000000b Name: SDS164 State: Connected, Joined IP: 10.107.100.64,10.107.100.164,10.107.101.64,10.107.101.164 Port: 7072 Version: 3.6.300 SDS ID: 055ae70f0000000a Name: SDS163 State: Connected, Joined IP: 10.107.100.63,10.107.100.163,10.107.101.63,10.107.101.163 Port: 7072 Version: 3.6.300 SDS ID: 055ae70d00000009 Name: SDS162 State: Connected, Joined IP: 10.107.100.62,10.107.100.162,10.107.101.62,10.107.101.162 Port: 7072 Version: 3.6.300 SDS ID: 055ae70c00000008 Name: SDS161 State: Connected, Joined IP: 10.107.100.61,10.107.100.161,10.107.101.61,10.107.101.161 Port: 7072 Version: 3.6.300 SDS ID: 055ae70b00000007 Name: SDS154 State: Connected, Joined IP: 10.107.100.54,10.107.100.154,10.107.101.54,10.107.101.154 Port: 7072 Version: 3.6.300 SDS ID: 055ae70a00000006 Name: SDS153 State: Connected, Joined IP: 10.107.100.53,10.107.100.153,10.107.101.53,10.107.101.153 Port: 7072 Version: 3.6.300 SDS ID: 055ae70900000005 Name: SDS152 State: Connected, Joined IP: 10.107.100.52,10.107.100.152,10.107.101.52,10.107.101.152 Port: 7072 Version: 3.6.300 SDS ID: 055ae70800000004 Name: SDS151 State: Connected, Joined IP: 10.107.100.51,10.107.100.151,10.107.101.51,10.107.101.151 Port: 7072 Version: 3.6.300 SDS ID: 055ae70700000003 Name: SDS144 State: Connected, Joined IP: 10.107.100.44,10.107.100.144,10.107.101.44,10.107.101.144 Port: 7072 Version: 3.6.300 SDS ID: 055ae70600000002 Name: SDS143 State: Connected, Joined IP: 10.107.100.43,10.107.100.143,10.107.101.43,10.107.101.143 Port: 7072 Version: 3.6.300 SDS ID: 055ae70500000001 Name: SDS142 State: Connected, Joined IP: 10.107.100.42,10.107.100.142,10.107.101.42,10.107.101.142 Port: 7072 Version: 3.6.300 SDS ID: 055ae70400000000 Name: SDS141 State: Connected, Joined IP: 10.107.100.41,10.107.100.141,10.107.101.41,10.107.101.141 Port: 7072 Version: 3.6.300 # scli --query_all_fault_sets --protection_domain_name PD01 Protection Domain has 6 Fault Sets: Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60200000000 Name: FS14 SDS Count: 4 SDS ID: 055ae70700000003 Name: SDS144 SDS ID: 055ae70600000002 Name: SDS143 SDS ID: 055ae70500000001 Name: SDS142 SDS ID: 055ae70400000000 Name: SDS141 Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60300000001 Name: FS15 SDS Count: 4 SDS ID: 055ae70b00000007 Name: SDS154 SDS ID: 055ae70a00000006 Name: SDS153 SDS ID: 055ae70900000005 Name: SDS152 SDS ID: 055ae70800000004 Name: SDS151 Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60400000002 Name: FS16 SDS Count: 4 SDS ID: 055ae7100000000b Name: SDS164 SDS ID: 055ae70f0000000a Name: SDS163 SDS ID: 055ae70d00000009 Name: SDS162 SDS ID: 055ae70c00000008 Name: SDS161 Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60500000003 Name: FS17 SDS Count: 4 SDS ID: 055ae7180000000f Name: SDS174 SDS ID: 055ae7170000000e Name: SDS173 SDS ID: 055ae7160000000d Name: SDS172 SDS ID: 055ae7150000000c Name: SDS171 Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60600000004 Name: FS18 SDS Count: 4 SDS ID: 055ae71c00000013 Name: SDS184 SDS ID: 055ae71b00000012 Name: SDS183 SDS ID: 055ae71a00000011 Name: SDS182 SDS ID: 055ae71900000010 Name: SDS181 Protection Domain ID: 22faf2a000000000 Fault Set: ID: 40ebe60700000005 Name: FS19 SDS Count: 4 SDS ID: 055ae72000000017 Name: SDS194 SDS ID: 055ae71f00000016 Name: SDS193 SDS ID: 055ae71e00000015 Name: SDS192 SDS ID: 055ae71d00000014 Name: SDS191
At the start of this post, I stated that the main purpose of Fault Sets is to provide protection against the failure of larger fault domain than a single node. In order to simulate the failure of a Fault Set in the lab environment, the simplest method was to power off a physical node.
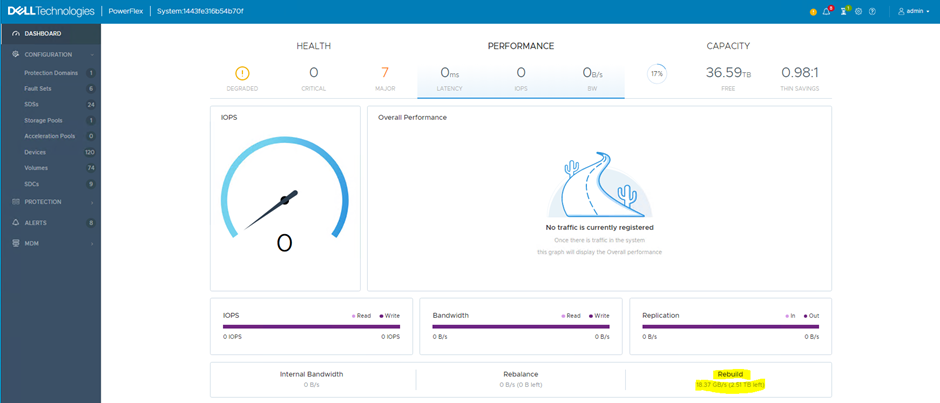
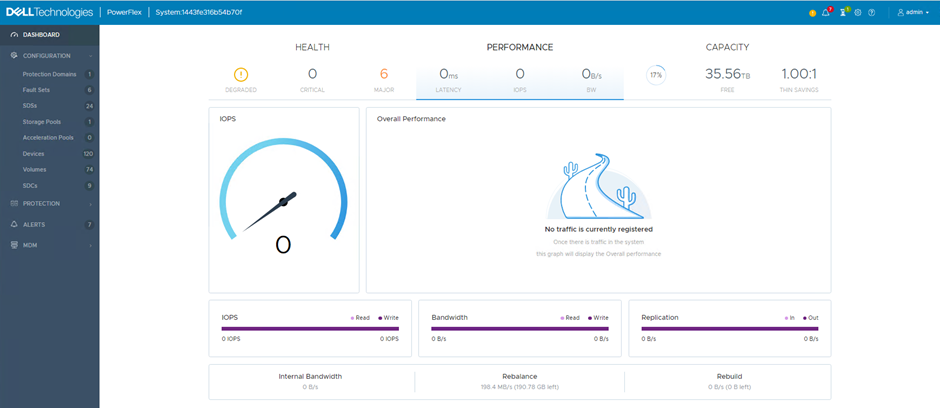
The PowerFlex environment immediately recognises the failure, it reports errors in the user interface and starts a rebuild. The user interface provides details of the network traffic being generated between nodes by the rebuild process. This network traffic can be significant, particularly if there are a lot of nodes in each Fault Set. They will all be working together, replicating the chunks that have become unmirrored due to the failure. The example shown here has limited network bandwidth due to this being a virtual environment with only six physical servers.
The network design is very important.
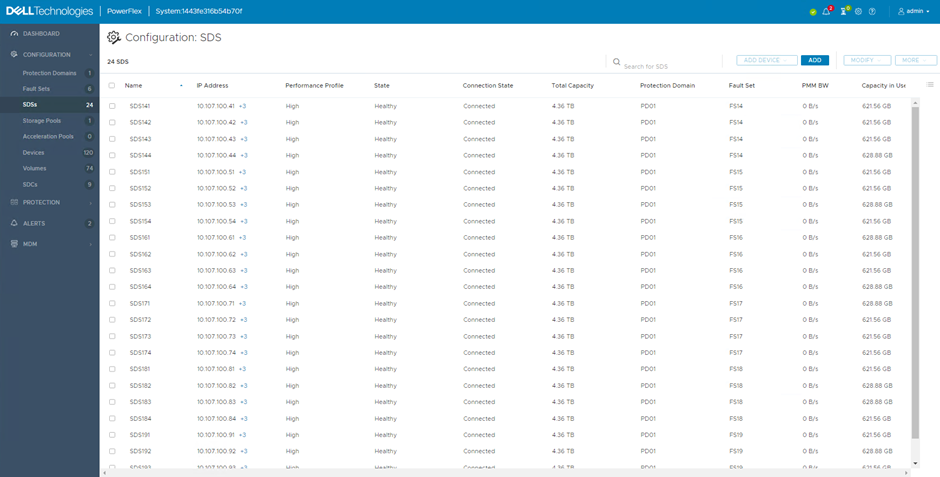
Whilst the rebuild is in progress, looking at the SDS screen within the user interface provides some insight as to what is happening. Under the ‘Capacity in Use’ column, the number alongside those SDS with an Error state will reduce over time, with the remaining nodes increasing. This shows the redistribution of the mirrors into the spare capacity.
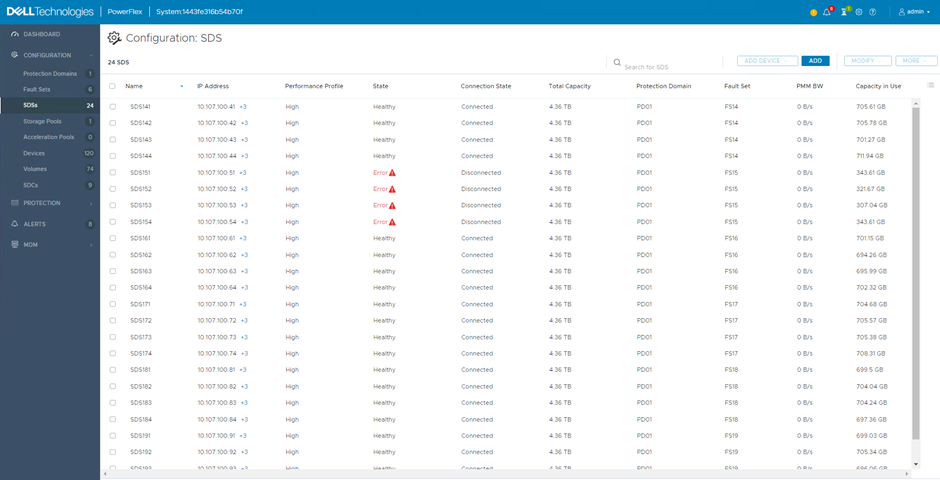
When the rebuild is complete, the nodes in the Error state show 0 Bytes used, the remaining nodes show roughly the same capacity used but this will even out over time as the rebalance process kicks in.
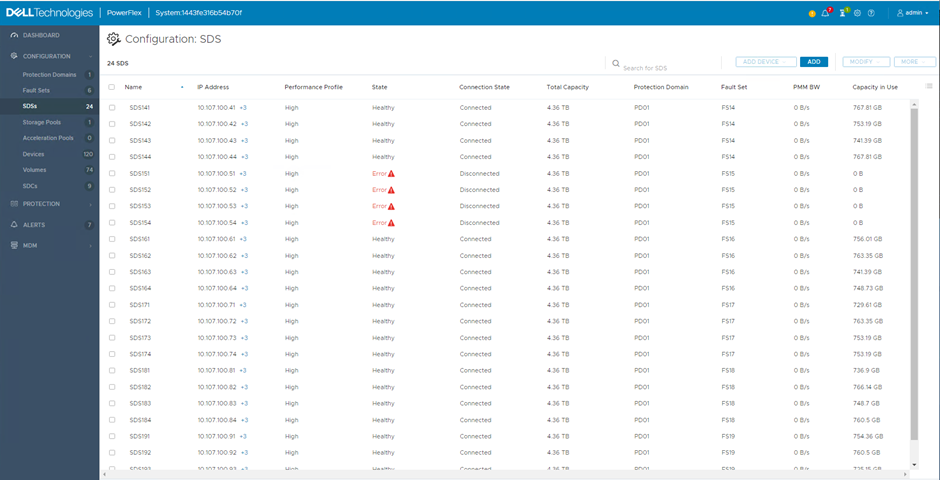
If the Fault Set recovers from its error state (in this lab environment, the physical server is switched back on), the PowerFlex system detects the return of the previously failed SDS nodes and immediately starts using them again. A rebalance takes place, moving chunks around so that the returning nodes and disks receive their fair share. Again, this can be viewed in the user interface, the Capacity in Use column will show an increase for the returning nodes and a decrease for all the others.
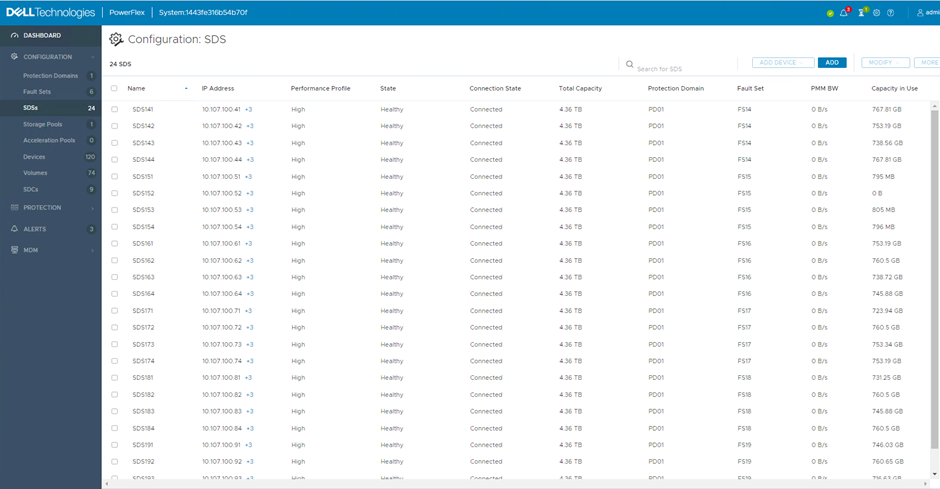
The second use case for Fault Sets that was mentioned above, was for maintenance purposes, an example could be an entire rack needing down time for electrical work.
It is already possible to place a single node into Maintenance Mode, either Instant Maintenance Mode (IMM) or Protected Maintenance Mode (PMM). I will not go into the details of each here but there is a simple ‘rule of thumb’, if you just want a quick reboot, use IMM, anything longer, use PMM.
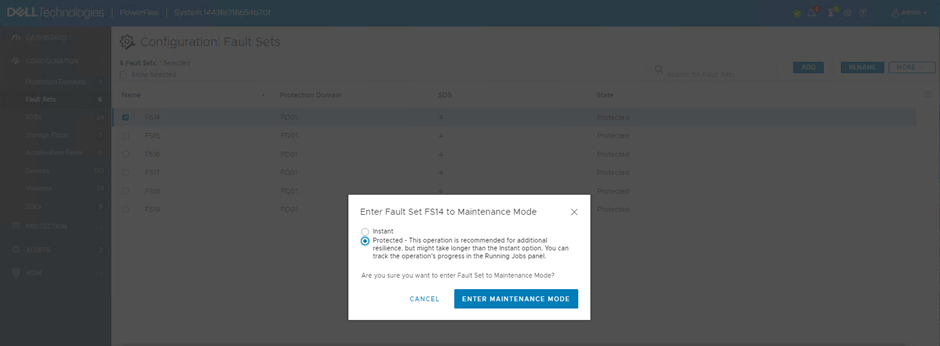
These Maintenance Modes can be applied to entire Fault Sets. They can be applied using the GUI, CLI or REST API, below the process using the GUI is shown. In the Fault Sets screen, under the ‘MORE’ option, select ‘Enter Maintenance Mode’
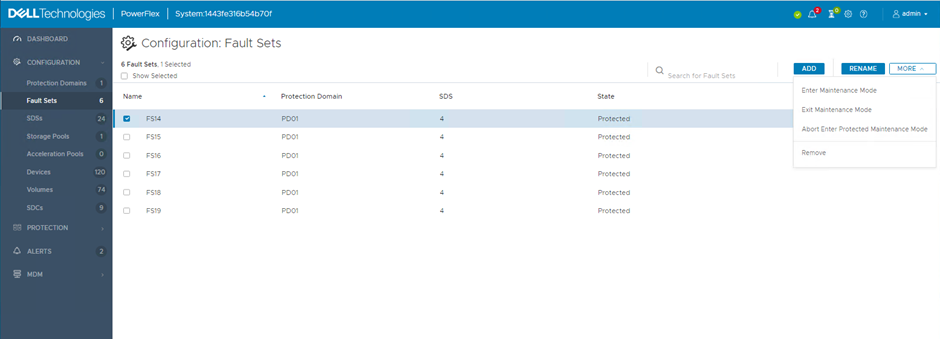
Choose either Instant (IMM) or Protected (PMM)
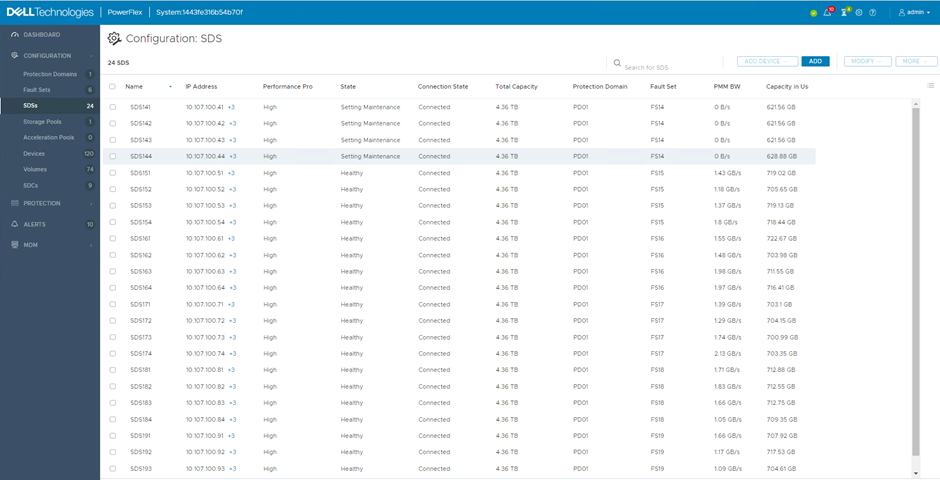
Once more, the SDS screen provides information around what is happening. The SDS nodes within the Fault Set put into maintenance show their state as ‘Setting Maintenance’ and since I selected Protected Maintenance Mode, the ‘PMM BW’ column displays the bandwidth created by the system creating additional mirrors of chunks impacted by the nodes entering maintenance.
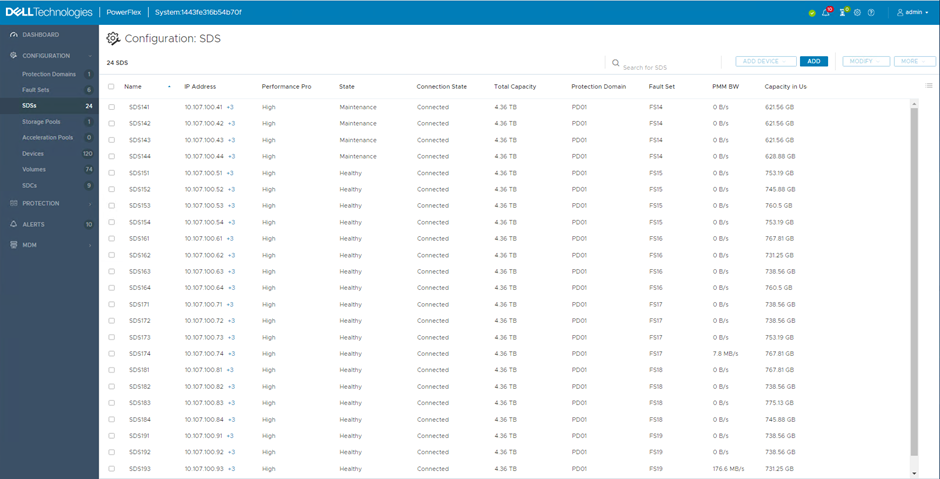
The process will complete and the SDS nodes will display ‘Maintenance’ in the State column. At this point, any required maintenance can be carried out.
Upon completion of the maintenance, the system can be returned to its optimal state, within the Fault Sets screen, select ‘Exit Maintenance Mode’ from the ‘MORE’ options.
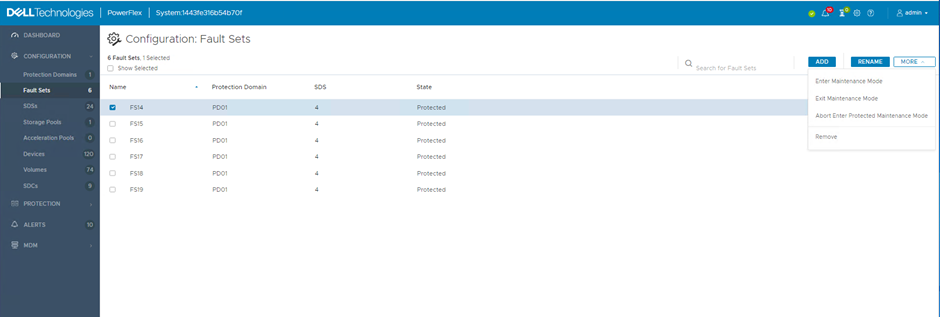
Confirm your choice
All SDS nodes will return to their fully functional ‘normal’ state.
All of the above tasks were carried out with zero interruption to service. The PowerFlex environment continued to provide storage to clients, throughout. There will have been an impact on performance as clearly resources within the environment were reduced temporarily.
Fault Sets provide yet another potential layer of resilience for PowerFlex storage, but their use and design must be thought through carefully. If you are interested in exploring this topic further, please contact me or one of the other specialists within the PowerFlex team here at Dell.
Many thanks for reading.

1 Response
[…] a great overview of what they are and how they work in a recent blog of his, that you can access here. However, what I will discuss in more detail in this blog are the implications of using Fault Sets […]